


作者&实验室

Chapter 1 Introduction
基于LLM的总结能力对text-based的基准数据集进行学习,以少量的文本数据就能针对用户喜好自定义household cleanup的清理分类规则。
-
Previous method:
- ask a person to specify a target location for every object , which is tedious and impractical in an autonomous setting. (Rasch et al., 2019; Yan et al., 2021)
- learn generic (non-personalized) rules about where objects typically go inside a house by averaging over many users. (Taniguchi et al., 2021; Kant et al., 2022; Sarch et al., 2022)
- Works that focus on personalization aim to extrapolate from a few user examples given similar choices made by other users, using methods such as collaborative filtering (Abdo et al., 2015), spatial relationships (Kang et al., 2018), or learned latent preference vectors (Kapelyukh and Johns, 2022).
旧方法的drawbacks: 需要搜集大量数据以及训练相应的模型。原文如下:
However, all of these approaches require collecting large datasets with user preferences or generating datasets from manually constructed, simulated scenarios. Such datasets can be expensive to acquire and may not generalize well if they are too small.
-
论文提出的方法
利用LLM的summarization capabilities对少量的用户偏好样本(基于文本的样本)进行学习便能总结出用户喜好的分类模式。
- Our approach is to utilize the summarization capabilities of large language models (LLMs) to provide generalization from a small number of example preferences. We ask a person to provide a few example object placements using textual input (e.g., yellow shirts go in the drawer, dark purple shirts go in the closet, white socks go in the drawer), and then we ask the LLM to summarize these examples (e.g., light-colored clothes go in the drawer and dark-colored clothes go in the closet) to arrive at generalized preferences for this particular person.
- By using the summarization provided by LLMs for generalization in robotics, we hope to produce generalized rules from a small number of examples, in a form that is human interpretable (text) and is expressed in nouns that can be grounded in images using open-vocabulary image classifiers.
优势:使用少量的文本数据就能学习用户的偏好模式;利用现成的大模型避免了昂贵的数据搜集以及模型训练;LLM具有令人惊讶的归纳总结能力
LLMs demonstrate astonishing abilities to perform generalization through summarization, drawing upon complex object properties and relationships learned from massive text datasets.
论文贡献:
(i) the idea that text summarization with LLMs provides a means for generalization in robotics,
(ii) a publicly released benchmark dataset for evaluating generalization 2 of receptacle selection preferences,
(iii) implementation and evaluation of our approach on a real-world mobile manipulation system.
Chapter 2: Related Work
-
Household cleanup 原来的有关Household cleanup的具身AI都需要模拟室内环境搜集大量数据以推测用户偏好(如物品随手摆放位置和物品分类所属的位置)。而该论文的方法可基于现有的LLM的常识和归纳总结能力快速推断出用户偏好。
-
Object sorting 典型方法:clustering(聚类)、active learning、metric learning(度量学习)、heuristic search(启发式学习)。这些典型方法实现了预定义的基于物理性质(颜color、shape、size、material)的分类规则。但无法实现基于语义和常识的分类。
[Høeg, S.H., Tingelstad](Høeg, S.H., Tingelstad, L.: More than eleven thousand words: Towards using language models for robotic sorting of unseen objects into arbitrary categories. In: Workshop on Language and Robotics at CoRL 2022 (2022)) 探索了使用LLM将物品进行更普适归类(general high-level categories)的能力。该论文类似地探索了LLM基于常识的分类能力。前者与后者的差别是前者基于一组预定义好的sorting rules,而后者能够自动推理出generalizable sorting rules.
-
LLMs for robotics
Many recent works study how LLM-generated high-level robotic plans (typically produced using the few-shot learning paradigm (Brown et al., 2020)) can be grounded in the state of the environment.
后续计划阅读该段提到的文章
列举了部分文章希望LLM能够输出一份通用的设置("one size fits all"),还有部分文章借助LLMs for PDDL planning来生成机器人的控制代码和逻辑。
核心都是将LLMs的常识集成到机器人系统中。
Chapter 3: Method
基于LLM通过少量用户偏好的例子,推理出容器的选择、操作基准的选择,以及如何将项目部署落地。
3.1 Personalized receptacle selection
给出几段例子,给到LLM的prompt以python代码形式化声明,以代码注释形式输出summary.
objects = ["yellow shirt", "dark purple shirt",
"white socks", "black shirt"]
receptacles = ["drawer", "closet"]
pick_and_place("yellow shirt", "drawer")
pick_and_place("dark purple shirt", "closet")
pick_and_place("white socks", "drawer")
pick_and_place("black shirt", "closet")
# Summary: Put light-colored clothes in the drawer and dark-colored clothes in the closet.再命令LLM根据summary对新的,没见过的物体进行分类。
3.2 Personalized primitive selection
类似地,可以命令LLM对不同的物体操作基准进行分类:
objects = ["yellow shirt", "dark purple shirt",
"white socks", "black shirt"]
pick_and_place("yellow shirt")
pick_and_place("dark purple shirt")
pick_and_toss("white socks")
pick_and_place("black shirt")
# Summary: Pick and place shirts, pick and toss socks.3.3 Real-world robotic system
命令LLM通过示范学习物体分类方法,和操作基准分类方法; 然后利用CLIP给最近的物体打上标签,移动到最近物体处,根据物体的类别确定该把物体放到哪里以及用什么样的操作进行放置

Chapter 4: Experiments
4.1 Benchmark dataset
测试了96个场景,均分为了4种类型的场景:living room, bedroom, kitchen, pantry room.
每个场景配置2-5个容器,4-10个seen object(即最初的训练样本,provided as input to the task),相同数量的unseen object。测试分类正确的频率。
提供了几种不同的分类方式,使用不同方法测试了各种分类方式的正确率,最后加权平均得到总正确率。
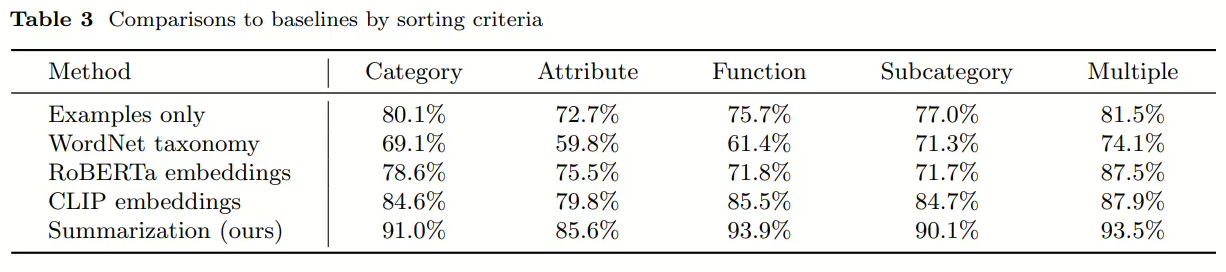
4.2 Baseline comparisons
-
Examples only: 直接给LLM提供seen的分类样例命令其分类unseen
-
WordNet taxonomy: 我理解为通过一个手工的词语分类库对各个物体进行分类
This baseline uses a handcrafted lexical ontology called WordNet (Miller, 1995) to generalize placements from seen to unseen objects. For each unseen object, we place it in the same receptacle as the most similar seen object, where similarity is measured using the shortest path between two objects in the taxonomy.
-
Text embedding: 使用预训练的模型协助分类。基于RoBERTa模型或者CLIP模型,通过物品名称的编码的余弦相似度来判断物品分类。
-
Summarization: 给LLM提供seen的分类样例,先命令其总结再命令其分类unseen。
4.3 Ablation studies
测试仅根据常识进行分类和根据总结进行分类,以及不同模型对实验结果的影响。以及测试人类手动生成的总结对性能的影响。
The goal of these experiments is to compare its performance to alternatives with far less information (using only common sense, without preferences) or far more information (using human-generated summarizations).
人类手动生成总结的分类效果最好,这预示着该方法后续可在改进summarization的方面改进性能
4.4 Real-world experiments
用户偏好以文本数据给到机器人,机器人在房间内实施分类并清理(把物品放到对应位置)
通过机器人顶部的两个摄像机估计机器人2D姿势$(x,\ y,\ \theta)$和物体2D坐标$(x,\ y)$. 机器人底座的姿态由安装在其顶板上的ArUco基准标记来估计。
物体的位置使用ViLD来进行检测。
每个场景中容器的位置烧录到硬件中。
机器人每次先靠近最近的物体,使其位于视野中央,然后通过物体名称编码和图像特征在CLIP embedding space中的余弦相似度来识别物体属于哪个category。LLM摘要中的对象类别集将自动提取并用作CLIP的目标标签集,如果没有来自LLM摘要的这些类别,人类将不得不手动指定可能存在于目标场景中的细粒度对象类的列表,以便使用CLIP进行对象分类。
根据LLM的分类将物体以合适的方法(place or toss)放进对应容器中。
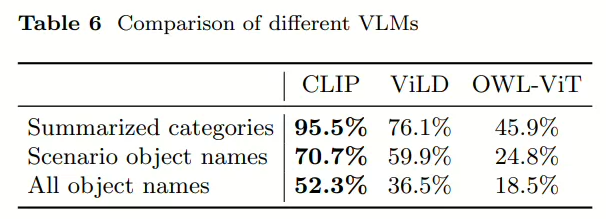
作者测试了不同VLM的效果:
4.5 Limitations
-
LLM在总结摘要时不可避免地会出错,最常见的情况是它仅仅列出了所有物体的名称,而没有对物体进行归类, 或者归类地太具体以至于不适用于unseen objects.
另一种常见的错误是在归类容器时会把多个容器归为一类,比如top drawer and bottom drawer会被归为drawers.
-
在real-world中的系统是被简化过的,操作基准由人预先制定好,只有上下的抓取,并且假定知道容器的位置。这些限制可以通过向系统中加入更多的操作基准,感知系统去尝试解决。此外,因为设定机器人不能踩过物体,所以在过度杂乱的房间里机器人将无法正常运转,可以改变每次拾取最近的物体这个策略去尝试解决。
叨叨几句... NOTHING